
PHOTO: SpaceX’s Starship lifts off from its launchpad at Boca Chica, Texas, on April 20. (Photo courtesy SpaceX)
We all acknowledge the importance of data in our modern world. Number-crunching has become one of America’s main activities, in scientific fields, in industry, in education, in government. Number-crunching successfully sent astronauts to the moon and back during the 1970s, and number-crunching was integral to the design and construction of the latest SpaceX rocket — the so-called Starship and its Super Heavy Booster — which attempted to blast into earth orbit yesterday.
SpaceX launched Starship, the world’s tallest and most powerful rocket, for the first time yesterday, April 20. Shortly after liftoff, an issue with the separation mechanism between the rocket’s two stages caused it to enter a spin, and it exploded moments later.
SpaceX owner Elon Musk had predicted the test failure, presumably based on data.
No doubt the failure will be analyzed to produce additional data. SpaceX has exploded a number of test rockets over the past few years, and learns something from every failure, I presume.
A couple of days ago, I crunched some numbers… not that I’m trained to crunch numbers, but I couldn’t find the data I wanted ‘already crunched’, so I crunched them myself… and produced a graph that purportedly shows the number of children and teens killed in school shooting incidents compared to the number killed by drug overdoses, and to the number killed by suicide.
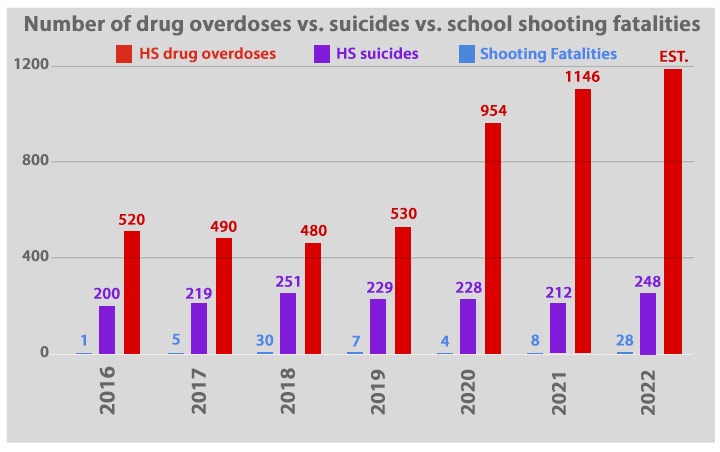
It appears that the number of high school student who die each year from drug overdoses has been twice to six times the number who die by suicide… and hundreds of times the number killed by gun violence in schools.
The numbers killed in school shootings include only students in high school and below, and does not include a shooter who dies during an incident. The suicides are teens only, as are the drug overdose deaths. As the chart indicates, the worst killer among us — among our youth — is not a crazy murderer with an AR-15.
I cannot vouch for the accuracy of these numbers. I’m a rank amateur when it comes to data.
But even well-trained data specialists occasionally explode multi-million-dollar rockets.
And as was discussed yesterday in Part One, the professional number-crunchers at Magellan Strategies were paid a lot of money to predict the outcome of an election campaign here in Archuleta County… numbers that, as it turned out, had very little relationship to reality.
Some of the biggest number-crunching controversies in recent years has concerned COVID-19. Were the vaccines properly tested, and did they truly protect people? Did mask-wearing make a significant difference? Were fatalities ascribed accurately? Did we properly assess the negative effects of a mass vaccination program? Were taxpayer revenues spent effectively, or was this a huge corporate boondoggle?
There’s plenty of data available, on both sides of each of these questions. It seems to be a matter of whom you want to believe, rather than what reality is supported by data.
I’m thinking back to 1962, in Oakland, California, where I was attending fifth grade at Grover Cleveland Elementary School, and found myself in the school cafeteria with a packet of printed test questions, a printed scoring sheet, and a number 2 pencil. If I’m not mistaken, this was the first year that the Oakland School District administered a test to students, district-wide, that would be scored by a computer.
Each question was accompanied by five possible answers, marked “A, B, C, D, or E”.
We understood that only one of the answers was the correct one, and we were told to answer as many questions as possible within the hour allotted to each test packet. We were encouraged to ‘guess’ at the correct answer if necessary, because after all, you had a 1-in-5 chance of accidentally picking the right answer. With a bit of common sense, we could figure out that, if the previous question’s answer was “B” then the next answer probably was not “B”.
Also, if there were two answers that seemed suspiciously similar, then one of them was probably the correct answer. Another chance for a reasonable guess.
We also understood that our score would be generated by a computer, not by a live person.
These were the early days of computerized data, when a computer could deal with five possible pre-selected answers. Apparently, counting to ‘five’ was the extent of a computer’s capabilities. Or so it seemed to me.
Today, our phones and computers handle a much wider range of tasks. Written and verbal communications. Shopping. Games. Photography and video. Advice. Monitoring. Maps and navigation. Translating languages. And most recently, computers are able to generate ‘original’ essays for high school and college students, grant writers, and corporate managers.
But a computer, despite its apparent capabilities, can only calculate numbers. A computer cannot actually “read” a sentence. Everything a computer does must be broken down into combinations of binary digits. “0s” and “1s”.
A computer ‘bit’ is either “On” or “Off”. So, in reality, a computer can only count up to “1”.
When we talk into our phones, or write a sentence, or take a photograph… the sounds, characters, and images are broken down into “0s” and “1s”, and are stored or sent as binary numbers.
In 2023, the life of a modern human being is controlled, to a large degree, by whatever can be converted into binary digits. That is to say, by ‘data’.
As has been suggested, ‘data’ is not always closely related to reality.
And what about the things cannot be converted into data? Are those things actually the most important things?